古籍整理平台 (Guji Platform)
🚧 项目正在积极开发中 — GitHub 仓库
古籍整理平台是一个基于 VS Code 的一站式古籍数字化整理工具,覆盖从资源采集、OCR 识别、文本校对到排版发布的完整七阶段流程。它将项目管理、自动化处理和协作编辑集成到一个统一的 IDE 插件中,让古籍数字化工作变得高效而规范。
为什么需要这个平台?
传统古籍数字化流程涉及多个独立工具和大量手工操作,效率低且容易出错。古籍整理平台将整个流程整合为一个统一的工作台,通过自动化和 AI 辅助大幅提升效率,同时保证数据的规范性和可追溯性。
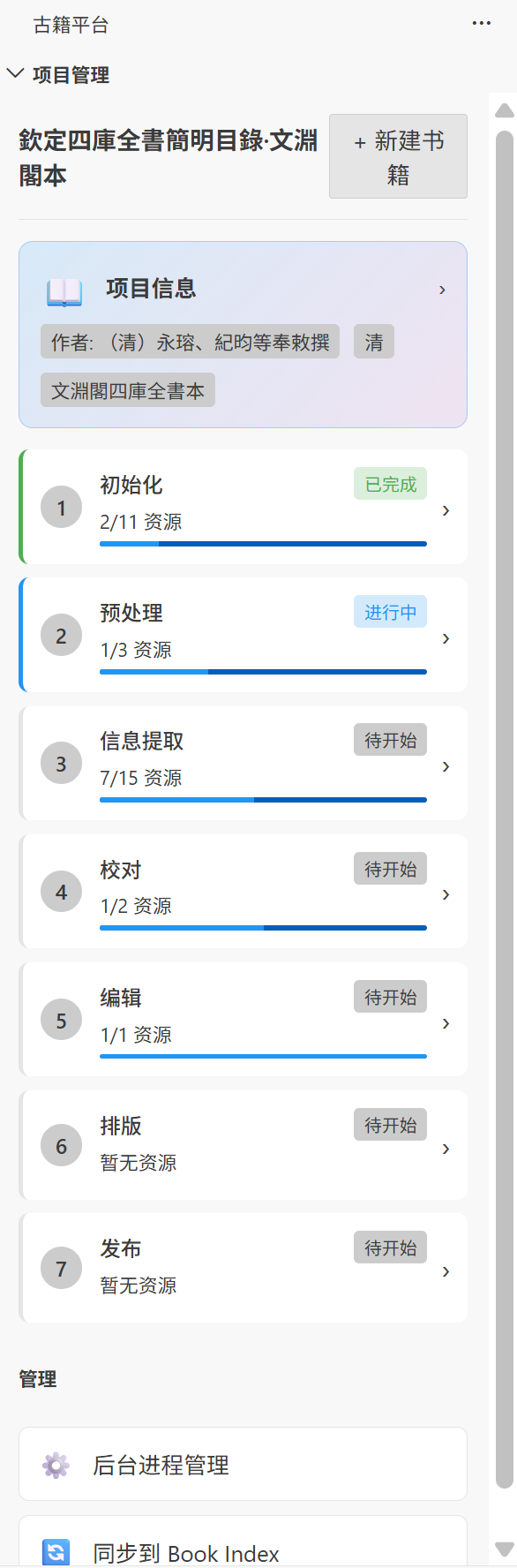
七阶段数字化流程
平台实现了完整的古籍数字化管线,每个阶段都有专门的可视化界面:
| 阶段 | 名称 | 说明 |
|---|---|---|
| 01 | 资源采集 | 从 CText、哈佛图书馆、Archive.org 等 14+ 站点下载文本和图片资源 |
| 02 | 预处理 | 图片增强、文本规范化、结构标准化 |
| 03 | 信息提取 | OCR 识别、TeX 文件生成、质量分析 |
| 04 | 校对 | 图文对照的精细化校对,支持异体字处理 |
| 05 | 编辑 | 添加标点、注释、翻译 |
| 06 | 排版 | 现代版式排版,通过 LuaTeX 实现 100% 复原古籍版式 |
| 07 | 发布 | 多格式导出与发布 |
核心功能
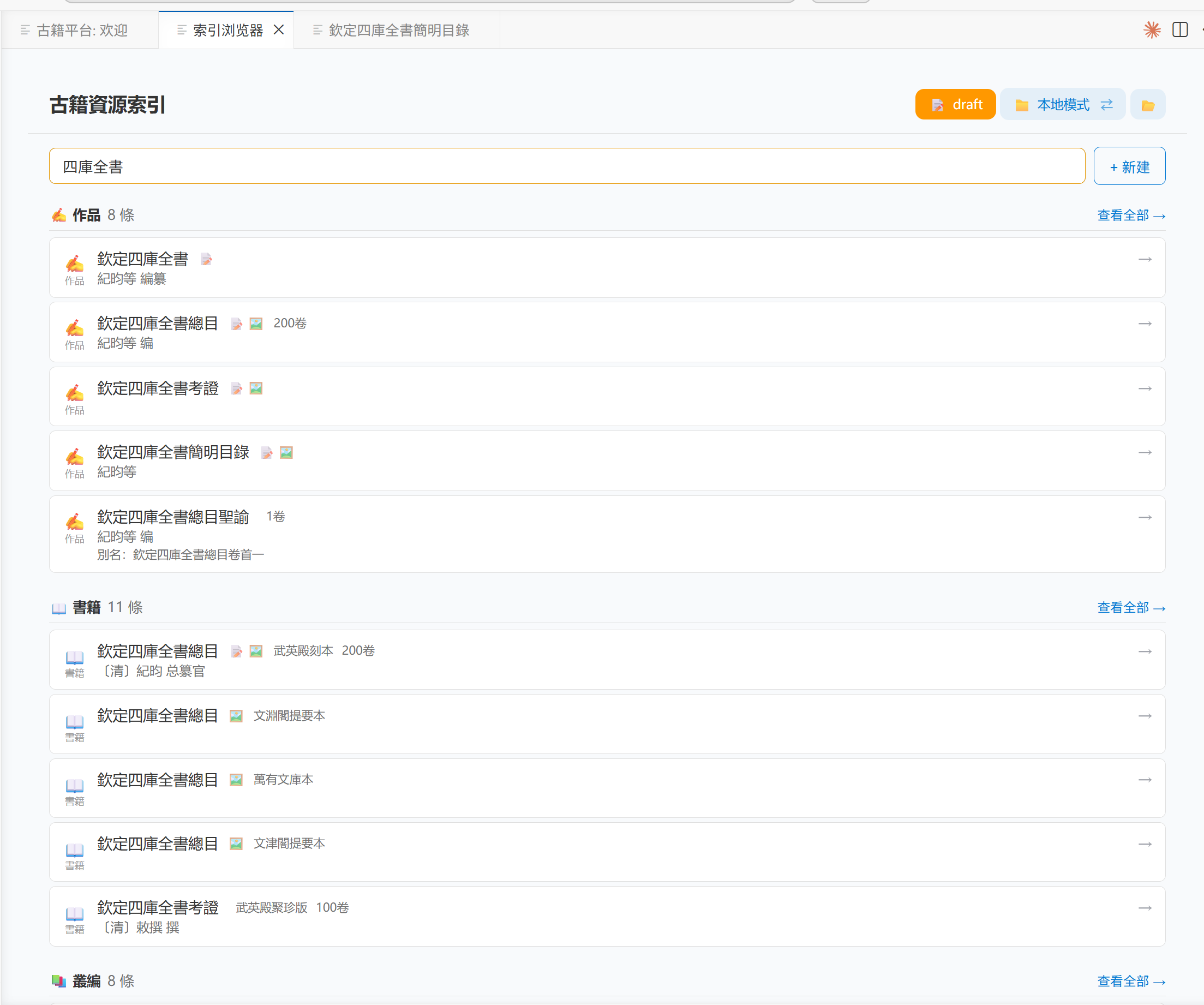
索引管理
采用三层层级模型:著作 (Work) → 丛书 (Collection) → 单书 (Book),配合 Snowflake + Base58 算法生成唯一标识符。支持本地文件夹和 GitHub 在线同步两种模式,内置索引浏览器,提供可视化检索。
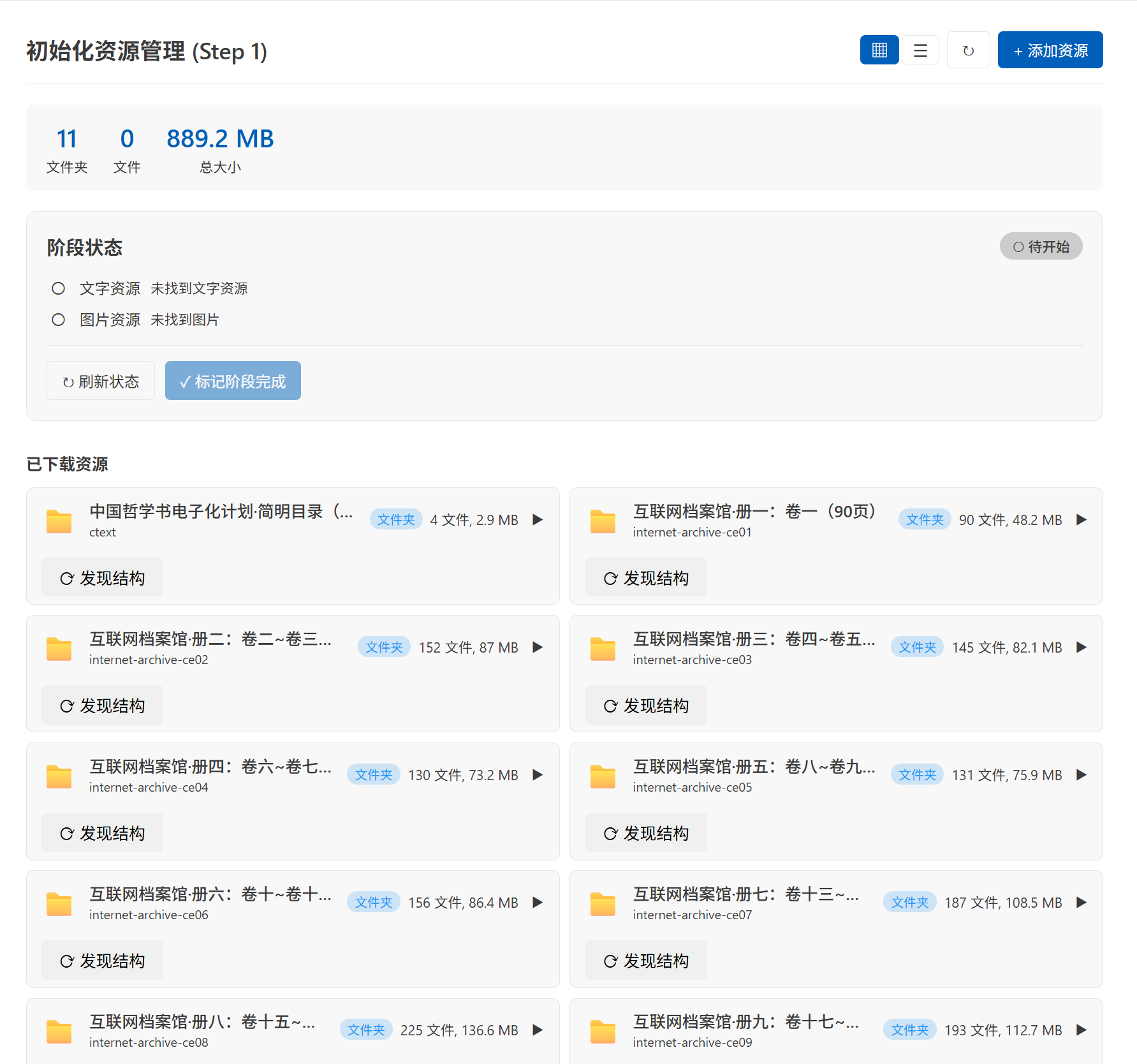
资源采集与下载管理
内置 14+ 网站适配器,支持从中国哲学书电子化计划 (CText)、哈佛图书馆、Archive.org 等主流古籍资源站批量下载。下载管理器提供实时进度监控、暂停/恢复/重试功能,并能智能提取元数据。
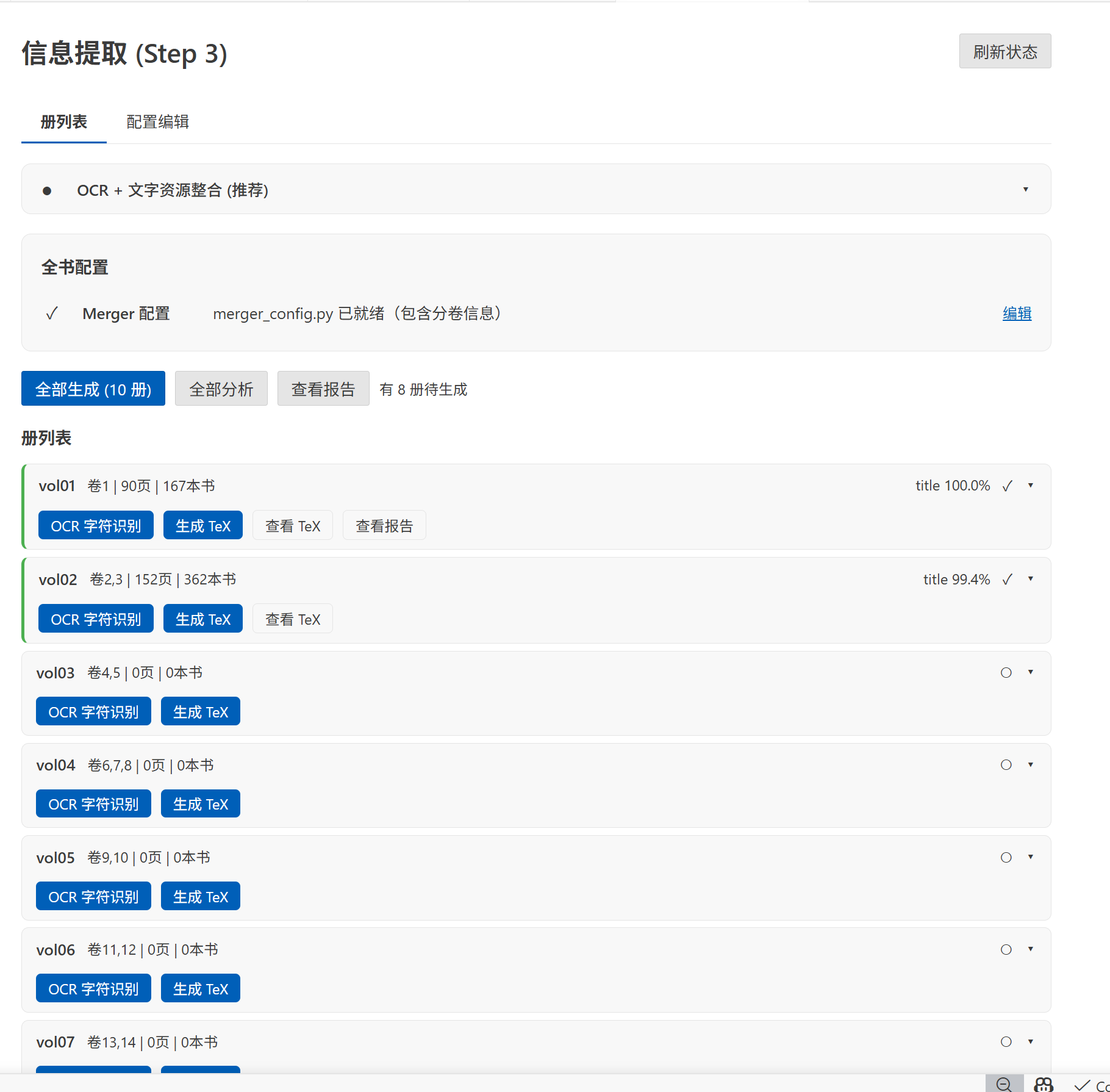
智能 OCR 与文本对齐
集成 open-guji-cv 图像处理引擎(基于 PaddleOCR),实现三层精确对齐:
- 册级对齐:一册 = 一个 TeX 文件 = 一组图像
- 页级对齐:TeX 输出页精确匹配扫描页
- 字级对齐:每个字符的网格坐标定位
通过 Merger 模块将 OCR 结果与文本自动对齐,生成高质量的数字化 TeX 文件,并提供标题匹配率、细节覆盖度等质量指标。
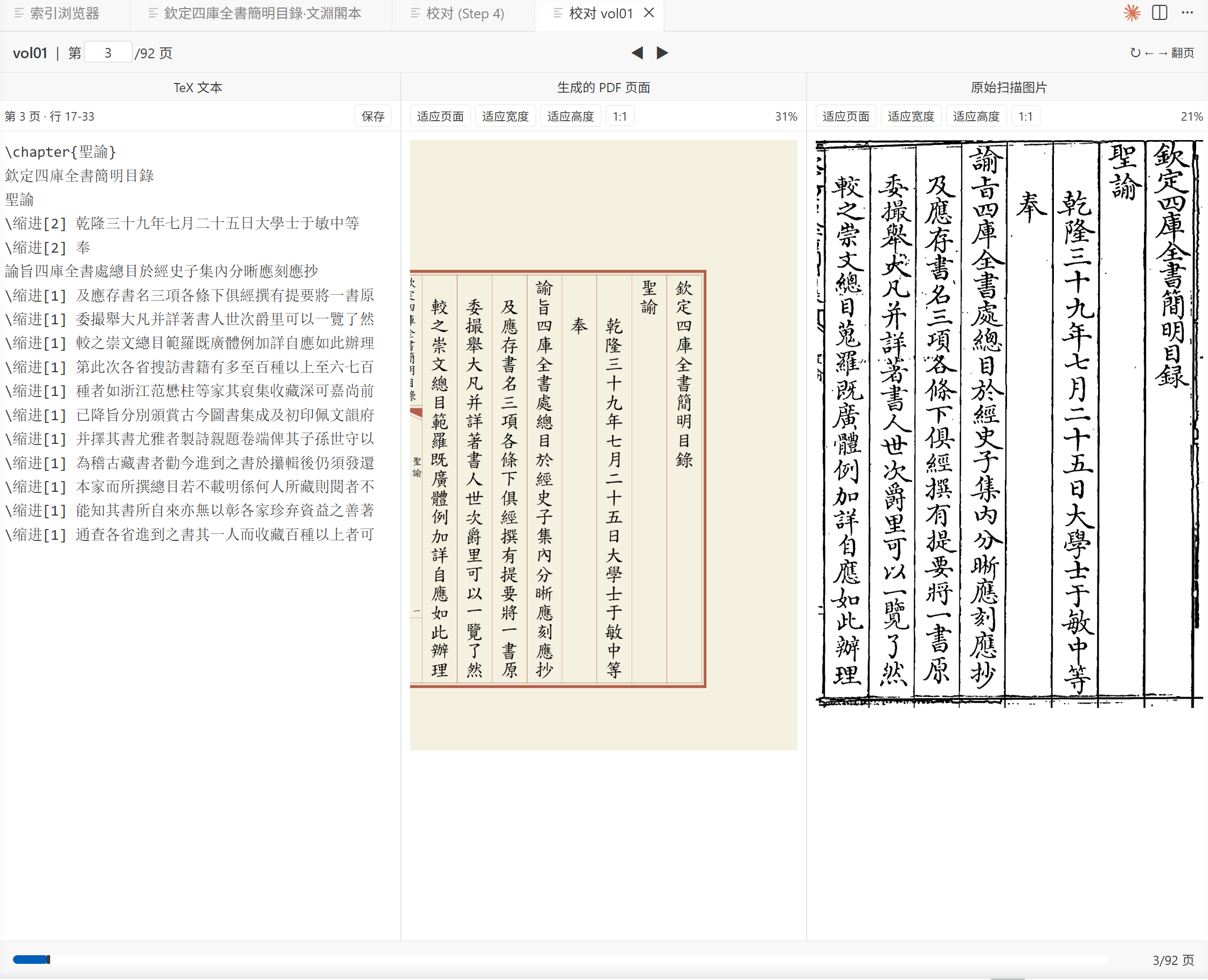
图文对照校对
提供多版本比较和可视化 diff 查看器,支持 OCR 位置感知高亮。校对人员可以在扫描原图和识别文本之间便捷切换,高效完成人工校验和错误修正。
AI 辅助
集成多种 AI 服务(Gemini / OpenAI / Ollama),用于:
- 元数据智能提取
- 自动断句与标点
- 实体识别(人物、地点、书籍等)
支持本地部署的 Ollama 模型,无需联网即可使用 AI 功能。
技术架构
| 层级 | 技术栈 |
|---|---|
| 前端 | TypeScript + React 19 + VS Code Webview API |
| 后端处理 | Python 3.8+ (PaddleOCR, LuaTeX) |
| UI 组件 | @vscode/webview-ui-toolkit + Tailwind CSS |
| 构建工具 | esbuild |
| 协作 | Git 版本控制 |
快速开始
环境要求
- VS Code 1.85.0+
- Python 3.8+
- Node.js 16+(开发时需要)
安装
目前处于开发阶段,可通过源码安装体验:
git clone https://github.com/open-guji/guji-platform.git
cd guji-platform
npm install
pip install -e .
在 VS Code 中按 F5 即可启动开发模式。
相关项目
| 项目 | 说明 |
|---|---|
| book-index | 古籍索引数据仓库 |
| open-guji-cv | 古籍图像处理与 OCR 工具包 |
| luatex-cn | LuaTeX 中文排版引擎 |
参与贡献
项目采用 Apache 2.0 开源协议,欢迎参与贡献!